 PDFBench, the first comprehensive benchmark for function-guided de novo protein design. Our benchmark systematically evaluates eight state-of-the-art models on 16 metrics across two key settings: description-guided design, for which we repurpose the Mol-Instructions dataset, originally lacking quantitative benchmarking, and keyword-guided design, for which we introduce a new test set, SwissTest, created with a strict datetime cutoff to ensure data integrity. By benchmarking across a wide array of metrics and analyzing their correlations, PDFBench enables more reliable model comparisons and provides key insights to guide future research.
PDFBench, the first comprehensive benchmark for function-guided de novo protein design. Our benchmark systematically evaluates eight state-of-the-art models on 16 metrics across two key settings: description-guided design, for which we repurpose the Mol-Instructions dataset, originally lacking quantitative benchmarking, and keyword-guided design, for which we introduce a new test set, SwissTest, created with a strict datetime cutoff to ensure data integrity. By benchmarking across a wide array of metrics and analyzing their correlations, PDFBench enables more reliable model comparisons and provides key insights to guide future research.
 PDFBench, metrics are categorized into 6 dimensions, and we show that none of the prior works have been evaluated across all dimensions. (b) Detailed view of the metrics in PDFBench, with several representative metrics from each dimension presented
PDFBench, metrics are categorized into 6 dimensions, and we show that none of the prior works have been evaluated across all dimensions. (b) Detailed view of the metrics in PDFBench, with several representative metrics from each dimension presented
In Table 5, Table 6 and Table 7, we report the benchmark results for the description-guided task on all 16 metrics. Findings are summarized as follows:
| Models | Perplexity | Repetitveness | Foldability | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PPL-ProtGPT2 ↓ | PPL-ProGen ↓ | PPL-RITA ↓ | Repeat ↓ | Rep-2 ↓ | Rep-5 ↓ | pLDDT ↑ | % > 70 ↑ | PAE ↓ | % < 10 ↑ | |
| Natural | 318.15 | 5.99 | 5.52 | 1.99 | 44.49 | 0.25 | 80.64 | 81.16 | 9.20 | 65.64 |
| Random (U) | 2484.04±4.53 | 21.71±0.00 | 22.14±0.01 | 0.72±0.01 | 34.59±0.03 | 0.01±0.00 | 22.96±0.04 | 0.16±0.04 | 24.85±0.01 | 0.56±0.03 |
| Random (E) | 3136.88±4.17 | 18.68±0.00 | 19.04±0.00 | 1.15±0.01 | 40.99±0.01 | 0.01±0.00 | 25.77±0.03 | 0.19±0.06 | 24.71±0.01 | 0.60±0.03 |
| ProteinDT | 1576.23±4.32 | 12.41±0.01 | 12.44±0.01 | 6.83±0.10 | 62.47±0.14 | 2.82±0.05 | 38.29±0.04 | 0.98±0.17 | 25.13±0.02 | 0.40±0.09 |
| Chroma | 1370.21±1.48 | 12.19±0.00 | 12.42±0.01 | 2.59±0.02 | 55.41±0.03 | 0.60±0.01 | 59.18±0.09 | 20.17±0.23 | 15.03±0.04 | 28.62±0.62 |
| PAAG | 2782.70±9.63 | 17.84±0.01 | 18.05±0.02 | 2.34±0.02 | 45.83±0.03 | 0.09±0.01 | 28.39±0.07 | 0.07±0.03 | 25.38±0.01 | 0.10±0.03 |
| Pinal | 308.97±0.68 | 5.81±0.02 | 5.78±0.02 | 12.83±0.13 | 58.26±0.16 | 4.73±0.06 | 75.25±0.19 | 68.93±0.33 | 10.96±0.10 | 58.41±0.38 |
| ProDVa | 415.64±7.40 | 7.63±0.09 | 8.83±0.17 | 1.92±0.05 | 35.65±0.15 | 2.81±0.13 | 76.84±0.17 | 76.27±0.59 | 8.67±0.05 | 67.65±0.43 |
| Models | Model-based Alignment | Retrieval-based Alignment | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ProTrek Score ↑ | EvoLlama Score ↑ | Soft(4) ↑ | Soft(10) ↑ | Soft(20) ↑ | Normal(4) ↑ | Normal(10) ↑ | Normal(20) ↑ | Hard(4) ↑ | Hard(10) ↑ | Hard(20) ↑ | |
| Natural | 27.00 | 60.33 | 98.50 | 97.17 | 96.09 | 93.72 | 89.01 | 85.11 | 43.23 | 33.20 | 29.78 |
| Random(U) | 1.03±0.04 | 36.22±0.07 | 28.09±0.83 | 12.62±0.29 | 6.94±0.20 | 28.97±0.38 | 12.83±0.52 | 7.16±0.29 | 25.95±0.52 | 10.57±0.40 | 5.38±0.39 |
| Random(E) | 1.04±0.05 | 34.11±0.10 | 28.35±0.62 | 12.83±0.51 | 6.73±0.66 | 28.97±0.62 | 12.59±0.29 | 6.84±0.39 | 25.79±0.45 | 10.39±0.67 | 5.46±0.45 |
| ProteinDT | 1.20±0.06 | 40.57±0.05 | 42.91±0.68 | 24.97±1.33 | 16.77±1.16 | 34.58±0.99 | 16.56±0.44 | 9.43±0.33 | 25.09±1.17 | 10.38±0.55 | 5.01±0.43 |
| Chroma | 2.10±0.02 | 40.10±0.23 | 29.54±0.59 | 13.43±0.18 | 7.41±0.22 | 29.63±0.58 | 13.26±0.50 | 7.44±0.21 | 25.51±0.47 | 10.68±0.43 | 5.73±0.19 |
| PAAG | 1.29±0.04 | 34.39±0.18 | 33.33±0.25 | 15.24±0.33 | 8.27±0.20 | 29.63±0.70 | 12.83±0.14 | 6.87±0.17 | 25.19±0.65 | 10.13±0.34 | 4.96±0.23 |
| Pinal | 17.50±0.09 | 53.40±0.31 | 82.42±0.45 | 74.44±0.63 | 69.99±0.67 | 71.69±0.59 | 63.53±0.24 | 58.43±0.48 | 29.51±0.31 | 17.89±0.26 | 14.17±0.27 |
| ProDVa | 17.40±0.06 | 51.19±0.17 | 85.64±0.06 | 77.37±0.44 | 72.75±0.61 | 77.52±0.28 | 66.67±0.37 | 59.03±0.44 | 27.84±0.71 | 15.77±0.29 | 12.11±0.28 |
| Models | Similarity | Novelty | Diversity | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GT-Identity ↑ | GT-TMScore ↑ | ESM-F1 ↑ | ESM-Precision ↑ | ESM-Recall ↑ | SeqEasy ↑ | SeqHard ↑ | StructEasy ↑ | StructHard ↑ | Seq ↑ | Struct ↑ | |
| Natural | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 36.11 | 4.90 | 38.51 | 13.56 | - | - |
| Random(U) | 0.37±0.03 | 16.95±0.03 | 71.06±0.02 | 81.66±0.02 | 63.46±0.02 | 98.77±0.03 | 58.14±0.07 | 96.82±0.03 | 77.64±0.12 | 97.01 | 81.59 |
| Random(E) | 0.23±0.04 | 17.10±0.00 | 71.95±0.02 | 82.51±0.02 | 64.35±0.02 | 98.45±0.01 | 60.19±0.14 | 96.25±0.04 | 76.82±0.10 | 99.56 | 81.45 |
| ProteinDT | 0.18±0.02 | 13.94±0.03 | 72.80±0.05 | 81.44±0.03 | 66.38±0.05 | 96.92±0.12 | 70.74±0.07 | 94.68±0.02 | 71.16±0.08 | 99.23 | 83.67 |
| Chroma | 0.22±0.04 | 17.93±0.02 | 72.82±0.02 | 80.22±0.03 | 67.06±0.01 | 97.28±0.02 | 58.68±0.09 | 80.99±0.04 | 51.06±0.21 | 96.13 | 79.9 |
| PAAG | 0.17±0.02 | 14.63±0.03 | 73.26±0.03 | 83.10±0.02 | 66.04±0.03 | 98.90±0.02 | 63.64±0.09 | 96.44±0.03 | 77.34±0.12 | 99.15 | 82.16 |
| Pinal | 18.65±0.15 | 23.75±0.14 | 76.63±0.06 | 77.74±0.08 | 75.99±0.06 | 55.55±0.19 | 43.82±0.22 | 40.07±0.33 | 17.23±0.23 | 82.96 | 72.73 |
| ProDVa | 21.48±0.15 | 20.03±0.11 | 75.23±0.01 | 77.01±0.05 | 74.11±0.02 | 38.23±0.31 | 14.64±0.23 | 56.18±23.36 | 36.31±33.02 | 83.29 | 36.92 |
In Table 1, Table 2, Table 3 and Table 4, we report the benchmark results for keyword-guided task. Based on these results, our key findings are as follows:
| Models | Perplexity | Repetitveness | Foldability | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PPL-ProtGPT2 ↓ | PPL-ProGen ↓ | PPL-RITA ↓ | Repeat ↓ | Rep-2 ↓ | Rep-5 ↓ | pLDDT ↑ | % > 70 ↑ | PAE ↓ | % < 10 ↑ | |
| guided with GO keywords | ||||||||||
| Natural | 554.35 | 9.17 | 8.89 | 2.17 | 44.43 | 0.43 | 76.92 | 72.44 | 10.54 | 54.69 |
| Random(U) | 2473.84±10.48 | 21.74±0.01 | 22.18±0.02 | 0.72±0.03 | 35.52±0.04 | 0.01±0.00 | 23.20±0.02 | 0.10±0.08 | 24.56±0.01 | 0.19±0.08 |
| Random(E) | 3096.13±18.42 | 18.68±0.01 | 19.05±0.01 | 1.14±0.04 | 41.45±0.07 | 0.02±0.00 | 25.99±0.12 | 0.05±0.08 | 24.47±0.03 | 0.24±0.08 |
| ProteoGAN | 2708.39±32.50 | 18.03±0.01 | 18.31±0.02 | 2.50±0.05 | 42.73±0.86 | 0.03±0.00 | 28.72±0.43 | 0.06±0.10 | 24.67±0.17 | 0.12±0.20 |
| CFP-Gen | 187.72±9.71 | 5.16±0.03 | 4.65±0.02 | 12.67±0.79 | 59.67±0.83 | 13.82±0.74 | 73.38±0.26 | 65.65±1.11 | 14.61±0.27 | 35.20±1.76 |
| ProteinDT | 1531.76±17.19 | 12.23±0.06 | 12.29±0.06 | 7.98±0.51 | 64.01±0.25 | 3.32±0.38 | 40.35±0.30 | 1.15±0.00 | 25.57±0.03 | 0.00±0.00 |
| Chroma | 1354.61±4.81 | 12.18±0.03 | 12.40±0.03 | 2.71±0.05 | 55.09±0.12 | 0.67±0.03 | 59.27±0.20 | 22.17±0.65 | 15.00±0.10 | 30.93±0.08 |
| PAAG | 2650.36±11.01 | 18.08±0.02 | 18.38±0.02 | 2.48±0.20 | 39.23±0.05 | 0.05±0.01 | 31.47±0.10 | 0.34±0.36 | 23.88±0.05 | 0.24±0.08 |
| Pinal | 414.26±77.15 | 6.85±0.59 | 6.89±0.64 | 14.13±2.58 | 59.84±4.37 | 4.85±1.63 | 72.58±5.55 | 62.10±14.24 | 11.79±2.52 | 52.19±12.03 |
| ProDVa | 486.77±9.51 | 11.16±0.29 | 18.71±0.77 | 1.87±0.07 | 22.04±0.09 | 0.88±0.05 | 74.73±0.24 | 68.40±0.38 | 6.11±0.02 | 84.90±0.46 |
| guided with IPR keywords | ||||||||||
| Natural | 611.99 | 9.73 | 9.47 | 2.23 | 44.05 | 0.48 | 75.77 | 68.85 | 11.13 | 50.92 |
| Random(U) | 2475.07±10.83 | 21.76±0.02 | 22.21±0.02 | 0.69±0.06 | 35.18±0.07 | 0.01±0.00 | 23.40±0.07 | 0.08±0.07 | 24.42±0.02 | 0.11±0.00 |
| Random(E) | 3104.89±24.07 | 18.67±0.02 | 19.05±0.02 | 1.16±0.02 | 40.91±0.08 | 0.02±0.01 | 26.29±0.18 | 0.08±0.07 | 24.34±0.03 | 0.19±0.07 |
| ESM3 | 330.44±9.90 | 6.33±0.07 | 6.59±0.07 | 28.13±0.24 | 68.98±0.42 | 21.11±0.47 | 60.90±0.77 | 32.93±2.43 | 16.73±0.27 | 22.68±1.83 |
| CFP-Gen | 135.57±4.51 | 4.94±0.12 | 5.03±0.11 | 11.86±0.29 | 59.17±0.57 | 13.57±0.88 | 76.36±0.35 | 72.52±1.45 | 12.54±0.26 | 47.23±2.51 |
| ProteinDT | 1506.64±5.70 | 11.87±0.02 | 11.93±0.02 | 10.02±0.38 | 65.68±0.30 | 5.83±0.39 | 37.59±0.15 | 0.04±0.07 | 26.19±0.03 | 0.00±0.00 |
| Chroma | 1336.19±7.55 | 12.17±0.01 | 12.39±0.02 | 2.60±0.08 | 54.53±0.08 | 0.54±0.03 | 59.76±0.26 | 23.75±1.35 | 14.67±0.05 | 31.38±0.75 |
| PAAG | 2748.12±25.25 | 17.85±0.04 | 18.06±0.03 | 2.32±0.11 | 44.78±0.06 | 0.08±0.01 | 30.89±0.03 | 0.11±0.11 | 24.98±0.02 | 0.19±0.13 |
| Pinal | 525.38±80.49 | 8.12±0.45 | 8.22±0.47 | 16.73±1.96 | 59.97±3.55 | 6.32±1.28 | 65.69±5.42 | 44.90±12.43 | 14.10±2.19 | 36.13±9.57 |
| ProDVa | 574.60±5.52 | 12.47±0.77 | 19.07±1.06 | 1.99±0.02 | 21.64±0.11 | 1.51±0.12 | 72.80±0.48 | 60.65±0.65 | 6.86±0.10 | 79.92±1.03 |
| guided with IPR&GO keywords | ||||||||||
| Natural | 534.49 | 8.96 | 8.66 | 2.16 | 45.01 | 0.44 | 77.17 | 73.15 | 10.48 | 54.9 |
| Random(U) | 2482.06±21.06 | 21.72±0.01 | 22.14±0.01 | 0.73±0.05 | 36.12±0.06 | 0.01±0.00 | 22.85±0.10 | 0.00±0.00 | 24.72±0.01 | 0.00±0.00 |
| Random(E) | 3120.95±10.54 | 18.68±0.02 | 19.03±0.01 | 1.14±0.03 | 42.08±0.02 | 0.02±0.00 | 25.60±0.06 | 0.00±0.00 | 24.59±0.02 | 0.00±0.00 |
| CFP-Gen | 163.51±6.62 | 5.23±0.04 | 5.23±0.07 | 13.14±1.18 | 59.86±0.53 | 14.17±0.32 | 72.70±1.07 | 60.90±1.11 | 14.45±0.28 | 42.69±1.76 |
| ProteinDT | 1697.89±9.15 | 12.81±0.05 | 12.87±0.05 | 6.81±0.17 | 63.58±0.36 | 2.91±0.21 | 36.46±0.31 | 0.20±0.17 | 25.75±0.06 | 0.00±0.00 |
| Chroma | 1360.90±5.58 | 12.19±0.04 | 12.40±0.04 | 2.53±0.12 | 55.65±0.16 | 0.56±0.05 | 58.71±0.59 | 19.29±2.67 | 15.33±0.30 | 29.72±1.34 |
| PAAG | 2807.41±13.89 | 17.80±0.01 | 17.98±0.02 | 2.32±0.04 | 47.64±0.24 | 0.09±0.01 | 30.05±0.27 | 0.00±0.00 | 25.69±0.10 | 0.00±0.00 |
| Pinal | 442.23±69.42 | 7.39±0.49 | 7.49±0.51 | 16.22±2.42 | 59.71±3.71 | 6.07±1.49 | 69.32±5.10 | 53.56±12.44 | 12.97±2.18 | 42.53±10.69 |
| ProDVa | 500.40±7.93 | 10.48±0.07 | 13.61±0.95 | 2.61±0.43 | 28.73±0.63 | 3.89±0.68 | 74.26±0.27 | 67.46±1.49 | 8.06±0.07 | 72.16±0.23 |
| Models | Model-based Alignment ↑ | Retrieval-based Alignment ↑ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ProTrek Score | IPR Recovery | GO Recovery | Soft(4) | Soft(10) | Soft(20) | Normal(4) | Normal(10) | Normal(20) | Hard(4) | Hard(10) | Hard(20) | |
| guided with GO keywords | ||||||||||||
| Natural | 21.6 | 100.0 | 100.0 | 94.52 | 92.78 | 89.75 | 87.59 | 77.49 | 69.41 | 37.23 | 28.72 | 26.7 |
| Random(U) | 4.29±0.04 | 0.00±0.00 | 20.79±0.37 | 30.06±1.33 | 14.00±4.45 | 7.50±2.57 | 26.89±1.83 | 10.00±0.08 | 5.05±1.44 | 30.01±3.21 | 9.72±0.46 | 5.05±0.29 |
| Random(E) | 3.44±0.01 | 0.00±0.00 | 11.71±1.48 | 29.87±0.50 | 12.41±2.18 | 6.69±1.04 | 27.08±0.30 | 11.06±0.55 | 5.96±0.98 | 28.62±2.22 | 11.98±0.66 | 5.87±0.79 |
| ProteoGAN | 4.42±0.02 | 0.00±0.00 | 14.99±1.36 | 38.64±2.86 | 19.84±2.14 | 10.27±1.11 | 32.70±1.42 | 13.84±0.69 | 8.13±0.52 | 27.16±1.67 | 10.90±1.05 | 5.65±0.53 |
| CFP-Gen | 10.03±0.33 | 9.67±1.07 | 18.98±1.14 | 66.24±2.17 | 57.40±1.85 | 47.39±3.10 | 53.46±2.49 | 38.87±2.00 | 30.09±0.92 | 27.80±3.72 | 13.37±0.74 | 8.15±0.42 |
| ProteinDT | 1.70±0.21 | 0.03±0.05 | 18.52±0.71 | 37.52±6.22 | 16.59±1.25 | 8.90±0.36 | 34.05±1.91 | 15.39±1.42 | 8.51±0.88 | 27.08±1.79 | 12.51±1.23 | 6.30±0.73 |
| Chroma | 1.84±0.03 | 0.23±0.05 | 16.33±2.36 | 32.13±0.79 | 13.80±2.03 | 7.74±0.87 | 27.90±0.96 | 12.07±1.06 | 5.92±0.38 | 27.99±0.43 | 12.22±0.92 | 5.15±0.82 |
| PAAG | 4.38±0.17 | 0.00±0.00 | 21.66±2.71 | 38.58±1.75 | 20.49±1.59 | 11.16±1.42 | 34.10±0.92 | 16.45±0.76 | 8.85±0.79 | 31.36±2.33 | 12.07±0.46 | 6.30±1.21 |
| Pinal | 12.69±1.42 | 19.26±1.90 | 22.76±1.78 | 73.98±4.37 | 61.90±8.29 | 56.66±7.96 | 61.52±4.86 | 49.93±3.82 | 42.95±3.35 | 35.88±4.96 | 21.26±2.48 | 17.89±2.27 |
| ProDVa | 14.42±0.07 | 20.22±0.14 | 30.24±0.75 | 86.48±1.78 | 71.38±5.34 | 55.80±0.60 | 66.43±0.58 | 52.38±0.66 | 45.07±0.30 | 35.93±3.38 | 21.45±2.75 | 18.13±0.96 |
| guided with IPR keywords | ||||||||||||
| Natural | 25.29 | 100.0 | 100.0 | 98.51 | 96.67 | 95.17 | 91.72 | 83.22 | 75.75 | 40.8 | 32.76 | 30.69 |
| Random(U) | 7.53±0.07 | 0.00±0.00 | 25.75±3.21 | 27.70±3.13 | 10.84±1.76 | 6.44±0.75 | 26.44±1.78 | 11.72±0.11 | 6.21±0.64 | 28.05±1.44 | 9.85±0.63 | 4.87±0.24 |
| Random(E) | 6.11±0.08 | 0.00±0.00 | 13.06±1.17 | 27.62±2.25 | 13.18±1.93 | 8.01±1.29 | 28.51±2.22 | 12.80±0.13 | 6.74±0.93 | 26.36±0.65 | 11.34±1.53 | 5.48±0.27 |
| ESM3 | 6.22±0.18 | 20.17±0.86 | 15.43±2.74 | 55.41±7.66 | 37.77±1.88 | 31.64±1.72 | 48.31±1.52 | 33.01±1.24 | 26.47±1.63 | 29.82±0.88 | 14.69±0.18 | 10.69±0.43 |
| CFP-Gen | 10.21±0.16 | 32.79±0.93 | 23.41±1.82 | 64.47±1.84 | 50.78±1.88 | 43.36±0.65 | 55.90±1.73 | 40.96±1.19 | 34.38±1.48 | 29.36±1.73 | 15.88±1.31 | 12.43±0.48 |
| ProteinDT | 3.85±0.03 | 0.08±0.05 | 20.76±1.46 | 40.38±3.85 | 22.68±1.32 | 13.83±0.98 | 34.44±0.29 | 16.13±1.04 | 9.23±0.58 | 26.82±2.94 | 10.92±1.66 | 5.63±1.41 |
| Chroma | 3.82±0.03 | 0.17±0.01 | 17.15±1.93 | 37.13±1.05 | 17.05±3.30 | 9.27±1.04 | 29.35±1.09 | 13.68±0.30 | 6.78±0.20 | 27.20±2.24 | 11.15±0.87 | 5.25±0.87 |
| PAAG | 5.98±0.17 | 0.08±0.05 | 13.85±1.02 | 32.07±3.27 | 14.41±2.50 | 9.58±1.78 | 30.69±2.26 | 14.37±1.85 | 7.78±0.86 | 26.90±0.92 | 11.46±2.17 | 6.05±0.87 |
| Pinal | 14.38±1.38 | 25.63±3.95 | 15.93±1.49 | 80.96±7.50 | 70.88±9.31 | 64.21±10.47 | 71.00±4.87 | 57.59±5.60 | 48.24±6.90 | 31.88±1.90 | 20.31±1.36 | 16.59±1.90 |
| ProDVa | 15.19±0.19 | 24.58±0.69 | 26.59±0.40 | 80.15±2.25 | 64.90±3.11 | 57.05±4.15 | 65.29±0.64 | 51.99±0.93 | 44.44±0.88 | 33.26±1.24 | 20.73±1.50 | 15.90±0.54 |
| guided with IPR&GO keywords | ||||||||||||
| Natural | 27.36 | 100.0 | 100.0 | 99.55 | 99.11 | 98.96 | 93.62 | 87.39 | 79.82 | 45.85 | 36.65 | 34.27 |
| Random(U) | 4.84±0.09 | 0.00±0.00 | 25.38±3.32 | 29.77±1.88 | 12.86±2.64 | 5.64±1.27 | 26.36±1.34 | 9.45±1.44 | 4.50±1.84 | 26.41±1.12 | 9.69±0.45 | 4.75±1.07 |
| Random(E) | 3.72±0.09 | 0.00±0.00 | 14.67±4.14 | 30.42±2.20 | 12.12±0.62 | 5.93±0.90 | 27.00±1.46 | 11.28±1.04 | 6.28±1.30 | 26.56±1.46 | 10.29±1.30 | 5.24±0.31 |
| CFP-Gen | 11.68±0.15 | 35.21±0.30 | 23.31±2.49 | 73.97±1.60 | 63.46±2.00 | 59.23±1.54 | 57.95±1.94 | 45.77±1.92 | 35.51±3.11 | 29.36±1.46 | 15.00±0.00 | 11.54±0.77 |
| ProteinDT | 3.06±0.11 | 0.36±0.03 | 15.92±1.14 | 47.08±1.20 | 29.13±1.43 | 19.63±1.63 | 38.72±1.43 | 19.29±0.68 | 9.99±0.97 | 27.45±2.32 | 10.48±0.69 | 5.39±1.09 |
| Chroma | 2.19±0.12 | 0.16±0.06 | 14.12±1.86 | 32.29±2.15 | 14.34±2.12 | 8.56±0.48 | 28.83±0.69 | 11.67±1.65 | 6.38±0.53 | 27.00±2.50 | 11.67±0.73 | 5.79±0.74 |
| PAAG | 4.66±0.12 | 0.02±0.02 | 9.77±0.90 | 28.24±3.82 | 14.14±3.71 | 7.22±2.06 | 28.19±1.67 | 11.82±0.82 | 6.03±0.60 | 29.08±1.80 | 12.17±1.55 | 6.08±0.51 |
| Pinal | 15.26±1.27 | 33.08±3.75 | 21.64±0.47 | 82.34±3.25 | 73.10±4.55 | 68.55±4.53 | 72.50±3.87 | 60.88±2.79 | 52.62±3.12 | 34.47±1.34 | 21.76±1.12 | 18.50±1.24 |
| ProDVa | 16.78±0.12 | 30.95±0.56 | 25.24±0.45 | 82.54±1.19 | 74.18±1.36 | 69.24±1.63 | 71.51±0.93 | 61.23±1.50 | 52.97±2.43 | 33.88±1.79 | 22.45±1.09 | 19.93±1.09 |
| Models | Similarity | Novelty | Diversity | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GT-Identity ↑ | GT-TMScore ↑ | ESM-F1 ↑ | ESM-Precision ↑ | ESM-Recall ↑ | SeqEasy ↑ | SeqHard ↑ | StructEasy ↑ | StructHard ↑ | Seq ↑ | Struct ↑ | |
| guided with GO keywords | |||||||||||
| Natural | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 44.34 | 4.07 | 56.96 | 18.15 | - | - |
| Random(U) | 0.84±0.23 | 16.76±0.05 | 73.37±0.04 | 82.81±0.05 | 66.40±0.03 | 98.66±0.07 | 58.04±0.69 | 96.54±0.11 | 76.75±0.20 | 94.29 | 81.56 |
| Random(E) | 0.63±0.16 | 17.03±0.03 | 74.24±0.04 | 83.70±0.05 | 67.24±0.03 | 98.44±0.04 | 60.28±0.09 | 95.85±0.15 | 75.92±0.19 | 98.65 | 81.54 |
| ProteoGAN | 0.28±0.07 | 14.75±0.24 | 74.25±0.07 | 84.37±0.10 | 66.84±0.05 | 99.13±0.06 | 65.24±0.27 | 96.19±0.17 | 75.82±0.29 | 98.94 | 84.37 |
| CFP-Gen | 2.30±0.25 | 13.98±0.26 | 67.52±0.17 | 68.36±0.26 | 67.46±0.30 | 59.60±0.61 | 47.85±0.95 | 54.07±1.87 | 28.28±1.47 | 85.14 | 81.76 |
| ProteinDT | 0.20±0.12 | 12.67±0.05 | 74.83±0.02 | 82.67±0.10 | 68.93±0.05 | 99.28±0.06 | 75.41±0.30 | 96.29±0.05 | 74.62±0.63 | 99.7 | 84.53 |
| Chroma | 0.38±0.07 | 17.67±0.06 | 74.29±0.02 | 80.80±0.02 | 69.15±0.02 | 97.44±0.16 | 59.35±0.58 | 80.22±0.45 | 50.88±0.84 | 93.7 | 79.79 |
| PAAG | 0.16±0.05 | 16.22±0.18 | 75.40±0.05 | 84.22±0.07 | 68.77±0.05 | 98.80±0.03 | 62.36±0.47 | 95.20±0.27 | 73.36±0.18 | 98.57 | 81.73 |
| Pinal | 5.35±0.35 | 15.84±0.47 | 71.36±0.66 | 72.24±1.85 | 71.06±0.46 | 61.98±8.67 | 46.06±5.23 | 46.42±9.10 | 19.27±6.43 | 87.61 | 79.0 |
| ProDVa | 9.07±0.14 | 20.25±0.13 | 72.54±0.10 | 75.81±0.06 | 70.25±0.12 | 48.37±0.72 | 25.02±0.81 | 62.12±0.19 | 32.72±0.02 | 98.17 | 35.76 |
| guided with IPR keywords | |||||||||||
| Natural | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 44.92 | 4.47 | 59.46 | 20.09 | - | - |
| Random(U) | 0.88±0.03 | 16.69±0.04 | 73.97±0.04 | 82.79±0.02 | 67.38±0.05 | 98.70±0.06 | 57.21±0.77 | 96.37±0.05 | 76.47±0.35 | 94.44 | 81.56 |
| Random(E) | 0.70±0.15 | 16.85±0.12 | 74.79±0.03 | 83.65±0.03 | 68.16±0.04 | 98.44±0.08 | 59.57±0.81 | 95.62±0.14 | 75.05±0.48 | 98.58 | 81.46 |
| ESM3 | 4.43±0.22 | 21.30±0.28 | 72.22±0.09 | 75.06±0.13 | 69.96±0.25 | 85.30±0.68 | 71.87±1.23 | 73.80±1.08 | 37.56±0.41 | 91.41 | 76.79 |
| CFP-Gen | 7.75±0.16 | 16.73±0.42 | 66.82±0.17 | 68.61±0.13 | 65.74±0.25 | 63.79±0.11 | 49.46±0.57 | 50.44±1.32 | 23.15±0.97 | 85.31 | 82.08 |
| ProteinDT | 0.13±0.02 | 12.38±0.06 | 75.23±0.04 | 82.13±0.08 | 70.07±0.02 | 99.08±0.13 | 73.57±0.65 | 96.64±0.12 | 76.03±0.19 | 99.71 | 84.81 |
| Chroma | 0.38±0.13 | 17.45±0.06 | 74.81±0.02 | 80.85±0.03 | 70.00±0.01 | 97.35±0.13 | 59.25±0.27 | 80.19±0.68 | 50.77±1.26 | 94.06 | 79.88 |
| PAAG | 0.26±0.07 | 14.37±0.07 | 76.19±0.01 | 84.43±0.03 | 69.93±0.03 | 98.93±0.07 | 64.71±0.70 | 96.66±0.16 | 79.23±0.22 | 99.16 | 81.48 |
| Pinal | 6.70±0.90 | 17.23±0.57 | 74.14±0.28 | 76.19±1.29 | 72.59±0.62 | 74.01±6.01 | 51.61±3.45 | 60.24±6.98 | 27.00±6.19 | 87.02 | 80.38 |
| ProDVa | 7.39±0.08 | 20.75±0.36 | 73.31±0.09 | 76.62±0.17 | 70.99±0.09 | 51.80±1.34 | 28.86±1.37 | 65.58±0.77 | 31.26±1.57 | 95.02 | 45.6 |
| guided with IPR&GO keywords | |||||||||||
| Natural | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 43.23 | 3.89 | 56.17 | 17.72 | - | - |
| Random(U) | 0.85±0.34 | 16.73±0.10 | 73.09±0.02 | 82.66±0.03 | 66.02±0.01 | 98.85±0.03 | 57.48±0.13 | 96.58±0.23 | 77.18±0.45 | 94.24 | 81.73 |
| Random(E) | 0.69±0.04 | 16.89±0.05 | 73.97±0.06 | 83.59±0.05 | 66.85±0.05 | 98.54±0.03 | 60.06±0.40 | 95.79±0.02 | 75.98±0.28 | 98.39 | 81.57 |
| CFP-Gen | 8.00±0.30 | 16.12±0.13 | 66.07±0.27 | 68.60±0.12 | 64.41±0.40 | 65.78±1.27 | 54.72±1.90 | 52.97±1.96 | 28.89±0.77 | 80.61 | 81.91 |
| ProteinDT | 0.29±0.14 | 13.08±0.03 | 74.91±0.02 | 82.88±0.06 | 68.91±0.06 | 98.75±0.06 | 71.44±0.50 | 96.53±0.05 | 75.73±0.21 | 99.39 | 84.18 |
| Chroma | 0.29±0.08 | 17.51±0.10 | 74.09±0.06 | 80.76±0.07 | 68.84±0.05 | 97.49±0.07 | 59.36±0.05 | 80.76±0.50 | 51.45±1.07 | 94.27 | 79.97 |
| PAAG | 0.20±0.08 | 13.77±0.07 | 75.52±0.05 | 84.45±0.05 | 68.81±0.05 | 99.12±0.06 | 65.07±0.68 | 97.22±0.09 | 81.53±0.18 | 99.22 | 81.51 |
| Pinal | 9.41±1.27 | 18.11±0.94 | 74.00±0.38 | 75.46±1.50 | 73.01±0.68 | 66.95±6.76 | 49.03±4.31 | 54.41±7.66 | 22.43±6.35 | 85.2 | 78.2 |
| ProDVa | 10.08±0.36 | 19.36±0.26 | 73.11±0.15 | 75.47±0.22 | 71.48±0.10 | 46.43±0.51 | 21.97±0.59 | 60.12±0.63 | 24.20±0.41 | 91.94 | 52.18 |
In this section, we provide a comprehensive analysis regarding the correlations among different evaluation metrics on PDFBENCH.
We begin by exploring to what extent sequence-level metrics reflect protein structures. Folding proteins into 3D structures using AlphaFold or ESMFold is time-consuming and requires substantial computational resources, particularly for longer sequences. Previous studies (ProtGPT2, ProGen2 and RITA) have observed a correlation between PPL and pLDDT scores. However, no empirical results or further analyses have been conducted to investigate the correlation.
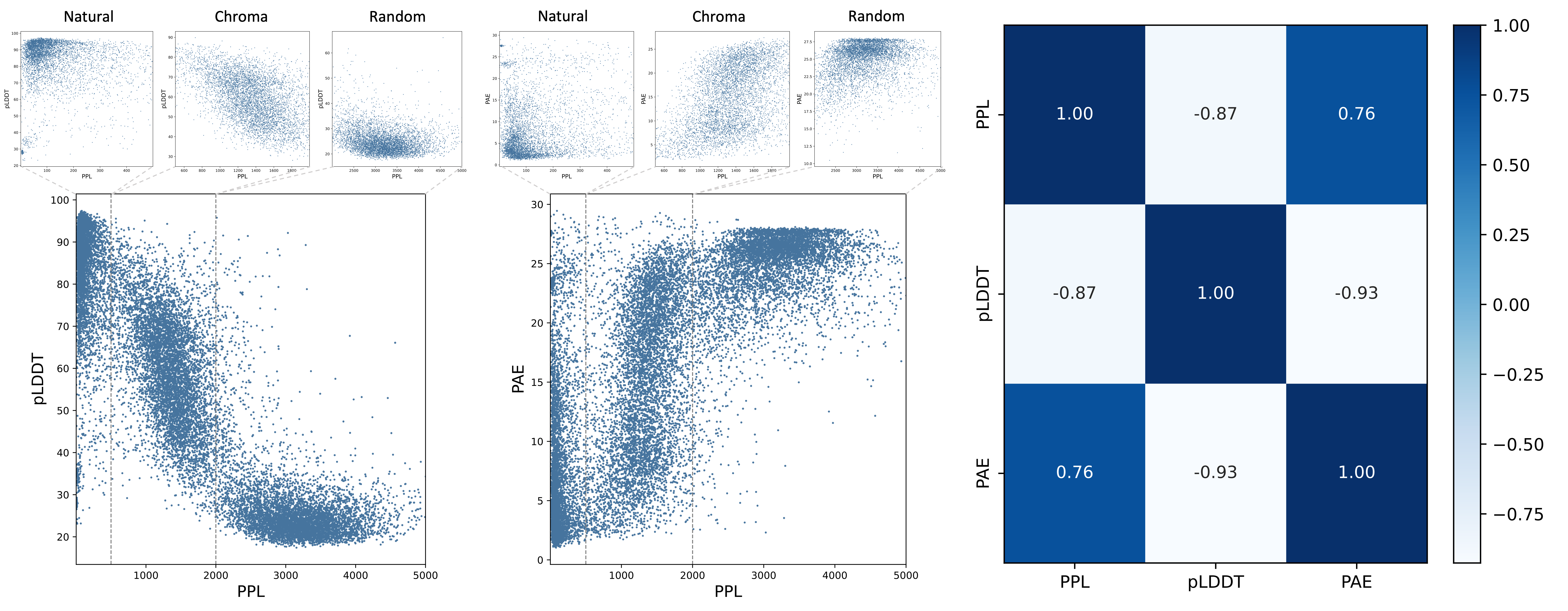
Results are randomly sampled from natural proteins with low PPL scores, Chroma-designed proteins with medium PPL scores, and randomly generated proteins with high PPL scores. Figure 3 presents the distributions of PPL, pLDDT, and PAE. Proteins with high pLDDT values are predominantly clustered in the low PPL range, whereas those with low pLDDT values are concentrated in the high PPL range. For the proteins situated between these two clusters, a negative correlation is observed between PPL and pLDDT values. Specifically, lower PPL values are generally associated with higher pLDDT scores. A similar pattern is observed in the distribution of PPL and PAE. Therefore, we empirically categorize PPL values into three ranges, denoted as low PPL range (values above 500), medium PPL range (values between 500 and 2,000), and high PPL range (values above 2,000). Additionally, the Pearson correlation in Figure 3(c) highlights the relationships between PPL, pLDDT, and PAE.
In the low PPL range, proteins are well-folded, exhibiting high pLDDT scores and low PAE values. In contrast, proteins in the high PPL range struggle to fold into plausible structures. Within the medium PPL range, proteins with higher PPL values tend to display lower pLDDT scores and higher PAE values.Previous research DPLM has found that repetitive patterns occurring in amino acid sequences may result in low pLDDT scores, thereby leading to lower structural plausibility. We conduct an empirical analysis using the Repeat metric to measure the correlation between this pattern and foldability. Proteins designed by ESM3 and Pinal exhibit repetitive patterns, as indicated by their high scores on the Repeat metric. Figure 4 presents the distribution of Repeat scores and pLDDT and PAE values for proteins randomly sampled from natural sequences and those designed by ESM3 and Pinal. One observation is that when the Repeat score remains relatively low, there is no clear relationship between Repeat and foldability. In other words, a low Repeat score does not necessarily indicate that a protein is well-folded. However, when the Repeat score exceeds 10, higher Repeat values are associated with lower pLDDT scores and higher PAE values. Therefore, it is important to maintain repetitive patterns below a certain threshold (e.g., Repeat < 10) when designing well-folded proteins.
The most reliable strategy for evaluating the alignment between designed proteins and input textual descriptions is through wet-lab experiments. However, such experiments are time-consuming and costly. Therefore, employing computational methods to screen proteins involves a trade-off between efficiency and accuracy. To more effectively evaluate the functions of designed proteins, both oracle model-based and retrieval-based metrics have been proposed.
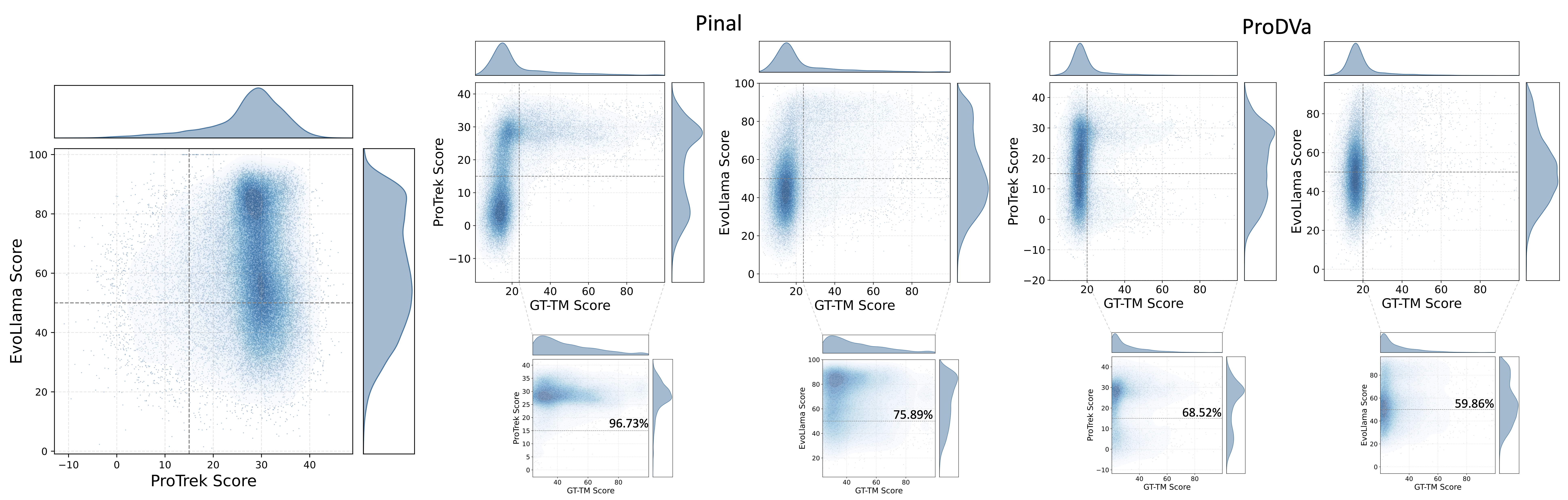
We first investigate whether the two oracle model-based language alignment metrics exhibit consistency in evaluating natural proteins. These two metrics differ in two key perspectives. First, the ProTrek Score measures similarity between ground truth and designed proteins directly based on their embeddings, whereas the EvoLlama Score assesses similarity through predicted functional descriptions. Second, ProTrek is an oracle model pre-trained on large-scale datasets without further fine-tuning on specific downstream tasks. In contrast, EvoLlama is trained from scratch on the downstream task, leading to a distinct intrinsic knowledge distribution between the two oracle models. Figure 5(a) illustrates the consistency between the ProTrek Score and the EvoLlama Score for natural proteins sampled from the validation and test sets of our description-guided task. The results show that most proteins are accurately predicted and tightly clustered in the upper-right corner, indicating strong agreement between the two metrics. Furthermore, following Pinal and the definitions introduced in Section~the metrics section, we establish empirical score thresholds to identify well-aligned proteins. Specifically, proteins with a ProTrek Score above 15 and an EvoLlama Score above 50 are considered to faithfully match the input functional descriptions.
The above discussion has remained focused on the global level of protein function. However, attention must also be directed toward local sequence alignment within proteins, particularly minor mutations in functional sub-sequences (motifs). To assess whether ProTrek is sensitive to protein mutations, we randomly select 1,000 natural proteins from \desctest and introduce random mutations with specified probabilities. The results are illustrated in Figure~6.
The ProTrek Score assesses both global alignment between the overall proteins and the functions, as well as local alignment between motifs and functions.Next, we discuss the language alignment metrics that do not rely on oracle models. The GT-TM Score measures the similarity between a designed protein and the ground truth structure. Since protein structure determines function, it is generally assumed that structurally similar proteins exhibit similar functions. However, we argue whether proteins with similar functions can fold into dissimilar structures. In Figures 5(b) and (c), proteins designed by Pinal and ProDVa are sampled for illustration. The average score reported in Table 5 is used as the threshold to determine whether the GT-TM score is considered high. It can be observed that 96.73% of the Pinal-designed proteins with high similarity to the ground truth exhibit high ProTrek scores (above 15), while 75.89% achieve high EvoLlama scores (above 50). A similar conclusion can be drawn from the ProDVa-designed proteins, demonstrating that high structural similarity leads to similar functions. Furthermore, for proteins with lower structural similarity, no correlation between the two similarities is observed.
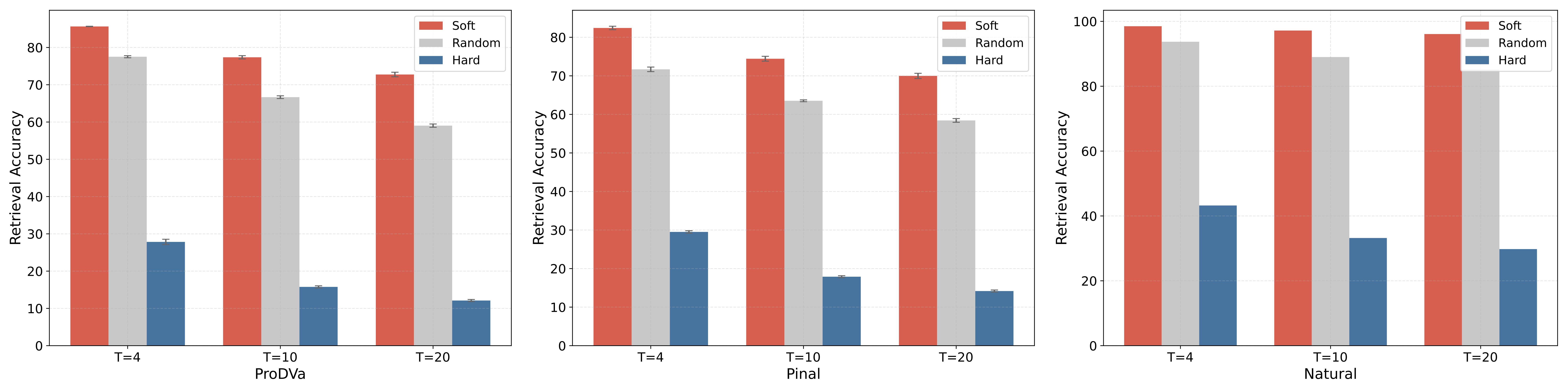
A high GT-TM Score generally indicates functional similarity among structurally similar proteins. However, high structural similarity is not a prerequisite for designing well-aligned proteins. Therefore, relying solely on this metric provides limited insight into whether the designed proteins align well with their functional descriptions.In addition to the aforementioned metrics, Retrieval Accuracy is a retrieval-based metric that measures whether the embeddings of the positive function-sequence pair are the most similar among all candidates. However, this metric is highly dependent on the retrieved sequences. To assess the extent to which the retrieval strategy influences the results, we further define Soft Retrieval Accuracy and Hard Retrieval Accuracy. The difference between them lies in whether the (T-1) most or least relevant texts and their corresponding sequences are retrieved in relation to the positive pair. The relevance between textual descriptions is defined by the cosine similarity of their embeddings. In Figure 6, for proteins designed by ProDVa and Pinal, the gap between Hard Retrieval Accuracy and Soft Retrieval Accuracy is 60.64% and 55.82%, respectively. Even for natural proteins, the gap between the two metrics on the ground truth can be as high as 66.31%. Therefore, the results demonstrate that the retrieval strategy significantly impacts performance.
@misc{kuang2025pdfbenchbenchmarknovoprotein,
title={PDFBench: A Benchmark for De novo Protein Design from Function},
author={Jiahao Kuang and Nuowei Liu and Changzhi Sun and Tao Ji and Yuanbin Wu},
year={2025},
eprint={2505.20346},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.20346},
}